

The TechBeat: Leader or No Leader, That is the Question (12/13/2025)
How are you, hacker? 🪐Want to know what's trending right now?: The Techbeat by HackerNoon has got you covered with fresh content from our trending stories of the day! Set email preference here. ## Exploiting EIP-7702 Delegation in the Ethernaut Cashback Challenge — A Step-by-Step Writeup  By @hacker39947670 [ 18 Min read ] How to exploit EIP-7702 delegation flaws: A deep dive into the Ethernaut Cashback challenge with bytecode hacks and storage attacks Read More.
By @hacker39947670 [ 18 Min read ] How to exploit EIP-7702 delegation flaws: A deep dive into the Ethernaut Cashback challenge with bytecode hacks and storage attacks Read More.
Code Review Anti-Patterns: How to Stop Nitpicking Syntax and Start Improving Architecture 
By @nikitakothari [ 5 Min read ] Code reviews are pricey. Let machines catch style issues so humans can focus on what matters: security, scalability, and architecture. Read More.
Measuring Non-Linear User Journeys: Rethinking Funnels Metrics in A/B Testing 
By @indrivetech [ 7 Min read ] A deep dive into user reorders, hidden behavioral patterns, and how aggregated funnels improve A/B test accuracy in non-linear user journeys Read More.
Before Bitcoin: The Forgotten P2P Dreams that Sparked Crypto 
By @obyte [ 5 Min read ] Before crypto, pioneers dreamed of decentralized money and fair sharing. Their wild ideas shaped today’s digital freedom. Go explore how it all began! Read More.
The Invisible Line Item: Why Pollution Is Missing From Every Balance Sheet 
By @chris127 [ 12 Min read ] For centuries, pollution has been the missing line item of our accounting. First from ignorance. Then from choice. Now, from necessity. We must account for it! Read More.
Earth Cleaning Technologies: The Current R&D Status and Why We're Still Losing the Race 
By @chris127 [ 7 Min read ] Imagine if you could reverse decades of pollution. Remove tons of CO₂, Clean oceans, restore forests at scale. The good news? We can! The bad news? We don’t! Read More.
Cantor8: Building The Future of Canton Network 
By @cantor8 [ 4 Min read ] Cantor8 is at the forefront of the surging growth of the Canton Network ecosystem. Endorsed by The Canton Foundation itself, the company is founded by a Cambrid Read More.
Not a Lucid Web3 Dream Anymore: x402, ERC-8004, A2A, and The Next Wave of AI Commerce 
By @mickeymaler [ 30 Min read ] Explains how x402, ERC-8004, and agent discovery turn APIs and AI agents into usage-based micro businesses. Web3's future is in Agents doing the work for you. Read More.
Hard Problems Are Easier, Once You Think Like This 
By @praisejamesx [ 7 Min read ] Stop being overwhelmed. Learn the neuroscience of mastery: how all genius works by compressing complexity into simple, automatic structures. Read More.
How I Found Sim Racing at Age 60 
By @wicked-racing [ 5 Min read ] How a 60-year-old former wannabe rally driver has found new youth through sim racing and the new available technology. Read More.
How To Get a First Name Domain for Less Than $101 
By @cv-domain [ 3 Min read ] Missed out on FirstName.com? .cv domain could be your last real chance to own your name online. Secure it now. Read More.
Everyone's Using the Wrong Algebra in AI 
By @josecrespophd [ 9 Min read ] From Tesla phantom braking to LLM hallucinations, the root bug is first-order math. We explain how dual/jet numbers unlock scalable second-order AI. Read More.
Leader or No Leader, That is the Question 
By @chris127 [ 9 Min read ] For most of human history, leaders were necessary. We needed them to coordinate, decide, organize and share their vision. But technology is changing this. Read More.
So You Want to Build a Writing Career? 
By @editingprotocol [ 4 Min read ] This comprehensive guide covers everything from finding your voice to mastering SEO. Learn how to turn your writing into a career asset with HackerNoon. Read More.
Can ChatGPT Outperform the Market? Week 18 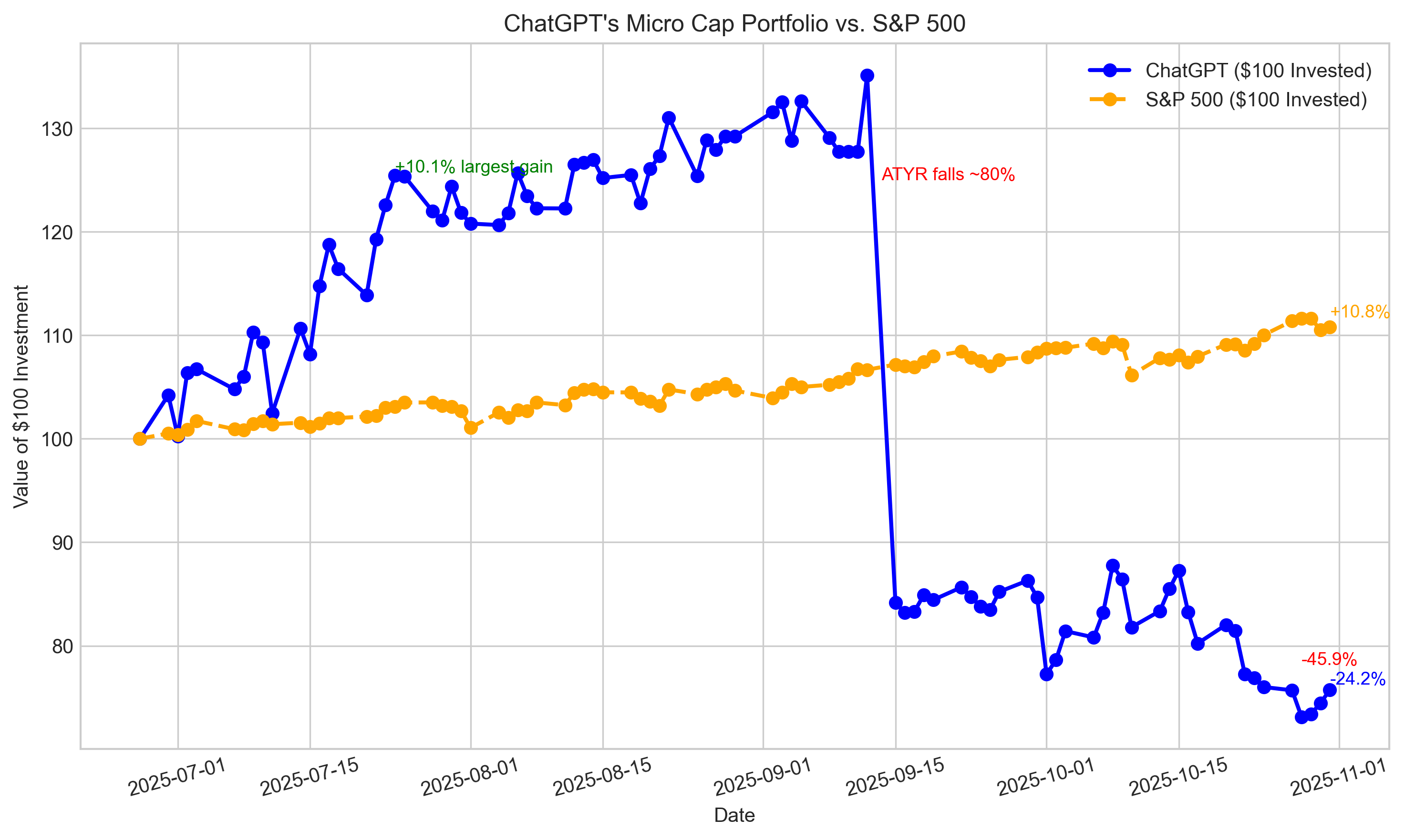
By @nathanbsmith729 [ 7 Min read ] Monday marked a new max drawdown of -45.85%. Read More.
Automated Content Moderation: How Does It Work? 
By @TheMarkup [ 7 Min read ] Shifting societal norms, technological advances, and the chaos of world events mean we may never reach an equilibrium where content moderation is solved. Read More.
12 Best Web Scraping APIs in 2025 
By @oxylabs [ 11 Min read ] Discover the 12 best web scraping APIs of 2025, comparing performance, pricing, features, & success rates to help teams scale reliable data extraction. Read More.
Agentic UX Over "Chat": How to Design Multi-Agent Systems People Actually Trust 
By @designchurchill [ 9 Min read ] Principles for designing agentic UX: verification, transparency, handoffs, and moving beyond chat interfaces. Read More.
AI: Quantum Computing Requires Conceptual Brain Science Research 
By @step [ 3 Min read ] To surpass AI before 2030, quantum computing can draw from conceptual brain science.
Read More.
Why I’m Tired of Productivity Wellness (And What It’s Doing to Our Minds) 
By @riedriftlens [ 4 Min read ] A founder’s critique of the productivity-wellness industry—from gamified focus apps to self-optimization culture—and why our minds crave clarity, not performanc Read More. 🧑💻 What happened in your world this week? It's been said that writing can help consolidate technical knowledge, establish credibility, and contribute to emerging community standards. Feeling stuck? We got you covered ⬇️⬇️⬇️ ANSWER THESE GREATEST INTERVIEW QUESTIONS OF ALL TIME We hope you enjoy this worth of free reading material. Feel free to forward this email to a nerdy friend who'll love you for it. See you on Planet Internet! With love, The HackerNoon Team ✌️ 
Ayrıca Şunları da Beğenebilirsiniz

How Football Became Crypto’s Biggest Gateway Drug

Zero Knowledge Proof’s Presale Auction Goes Viral While Chainlink & Ethereum Trade Flat
