

Ripple advances protocol safety with new XRP Ledger payment engine specification

Ripple has taken a major step toward hardening protocol safety on the XRP ledger, unveiling a detailed blueprint for its core Payment Engine as the network prepares for more complex features.
Ripple publishes first formal Payment Engine specification for XRP Ledger
Ripple has released the first formal specification of the XRP Ledger‘s Payment Engine, positioning it as a foundational upgrade as XRPL enters a more feature-dense era.
The document, published in partnership with formal methods firm Common Prefix, aims to serve as the canonical reference for how payments and cross-asset value transfer behave directly on-ledger.
XRPL has operated for more than a decade without downtime, yet Ripple argues this operational record is still not equivalent to provable correctness. In a DEV Community post dated Dec. 17, published under the RippleX Developers banner, the authors write that “to prepare the ledger for the next generation of complex features, we must move beyond empirical success to mathematical certainty.”
That said, the tone of the announcement is sober and technical rather than celebratory. For most of XRP Ledger history, the C++ implementation (XRPLD) has effectively functioned as the only definitive source of truth for core behavior.
However, Ripple’s post highlights a key limitation of this approach: “The code tells us, in very precise C++ terms, what it does. It does not always tell us why.”
From code-as-truth to explicit design intent
When source code doubles as the de facto specification, it becomes difficult to distinguish deliberate design choices from historical behavior that merely persisted because nothing failed. Moreover, this ambiguity grows more dangerous as new protocol amendments are layered into a live, globally used system.
Ripple points to a growing pipeline of advanced features, including lending, DEX-related work tied to Multi-Purpose Tokens (MPTs), batch transactions, and permissioned DEX concepts. As these modules “weave into the decades-old logic of the ledger,” the number of possible system states expands rapidly, increasing the risk of subtle failures if behavior is not rigorously specified.
The newly published payment engine specification, hosted on GitHub and labeled as work in progress, is framed as a serious technical artifact “intended for developers implementing or verifying XRPL payment system behavior.” It also distills the Payment Engine’s role into plain language: it “figures out how value should travel and then carries out those moves,” orchestrating flows across trust lines, MPTs, order books, AMMs, and direct XRP balances.
XRP Ledger: human-readable spec and machine-verifiable model
The deeper ambition behind this document is what it unlocks next. Ripple outlines a two-part target: first, a human-readable specification that reduces ambiguity and becomes the canonical reference for builders, node operators, and researchers. Second, a machine verifiable model, a mathematical representation of that specification, capable of supporting mechanical proofs about system properties.
With such a model, engineers can check whether proposed changes threaten core protocol safety guarantees before those changes ever hit production code. Moreover, this approach opens the door to more robust testing, automated reasoning about system behavior, and higher assurance for mission-critical financial infrastructure built atop XRPL.
Ripple is explicit about scope control. The team argues that attempting to formally specify the entire ledger in one effort “would be prohibitively expensive and time-consuming.” Instead, the work initially focuses on what are described as the two most critical and complex components: the XRPL payment engine and the Consensus Protocol.
Consensus as non-negotiable infrastructure
The XRPL consensus protocol is framed as non-negotiable infrastructure at the center of the network. Ripple describes consensus as “the heart of the ledger,” stressing that its correctness is “non-negotiable” and underpins the safety and liveness of the entire system.
The stated objective is to create a formal model of the mechanism to prove properties such as liveness, safety, and finality.
However, Ripple emphasizes that the current publication is the starting line, not the finish. After publishing the Payment Engine specification, the team plans to begin formal verification XRPL work on both the Payment Engine and the Consensus Protocol in 2026.
In this roadmap, the XRP ledger Payment Engine specification serves as the first major pillar in a shift “from code-as-truth to mathematics-as-truth.” That shift, Ripple argues, is essential as the ledger absorbs more complex DeFi-style functionality, institutional integrations, and long-lived financial contracts that demand strong safety guarantees.
Community reaction and market snapshot
The response from the XRP community has been enthusiastic. An XRPL validator and community member hailed the effort as an “absolute freaking game changer! … Aerospace & military grade security incoming,” noting that the ledger is receiving its first formal specification for the payments engine and that, by mathematically specifying key protocol components, this becomes “the enabler for the endboss of audits AND for other things like complex features or client diversity.”
At press time, XRP traded at $1.83, according to price data referenced alongside a chart sourced from TradingView.com. Moreover, Ripple’s announcement signals a broader evolution in how major blockchain networks manage technical risk, elevating formal methods from research interest to production roadmap.
In summary, Ripple’s collaboration with Common Prefix on a formal Payment Engine specification marks the first step in a multi-year push toward mathematically grounded assurance for XRPL’s core components, with formal verification work on the Payment Engine and Consensus Protocol targeted to begin in 2026.
You May Also Like

The Stunning ASEAN Winner Emerges As Manufacturing Shifts Accelerate
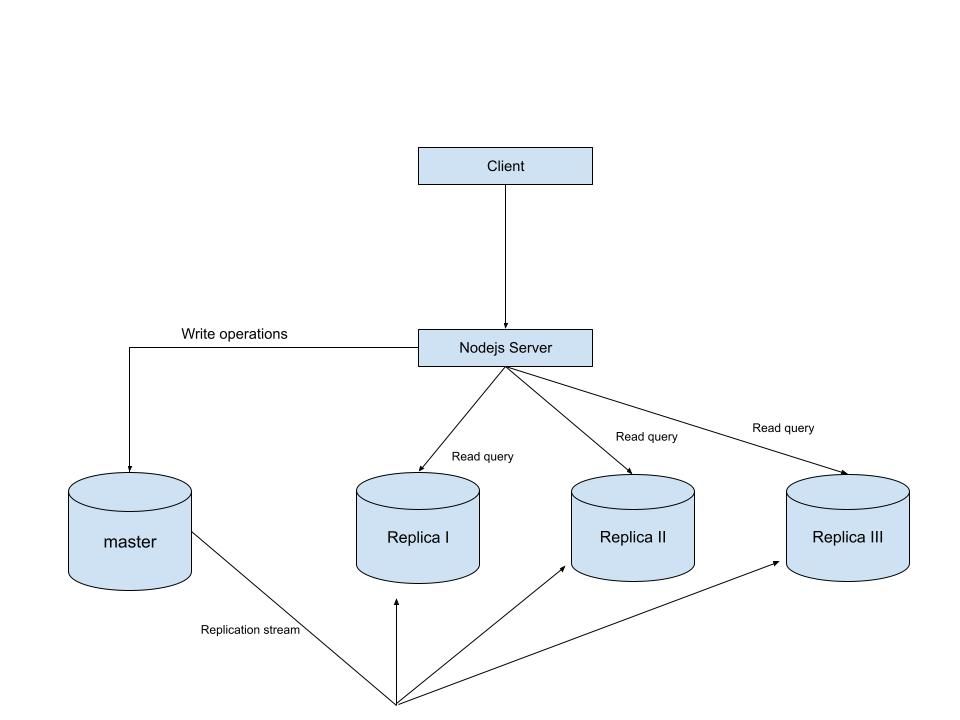
MySQL Single Leader Replication with Node.js and Docker
command: --server-id=1 --log-bin=ON The --server-id option gives each MySQL server in your replication setup its own name tag. Each one has to be unique and without it, replication won’t work at all. Another cool option not included here is binlog_format=ROW. This tells MySQL how to keep track of changes before passing them along to the replicas. By default, MySQL already uses row-based replication, but you can explicitly set it to ROW to be sure or switch it to STATEMENT if you’d rather log the actual SQL statements instead of row-by-row changes. \ Run our containers on docker Now, in the terminal, we can run the following command to spin up our database containers: docker-compose up -d \ Setting Up Our Master (Primary) Server To configure our master server, we would have to first access the running instance on docker using the following command docker exec -it mysql-master bash This command opens an interactive Bash shell inside the running Docker container named mysql-master, allowing us to run commands directly inside that container. \ Now that we’re inside the container, we can access the MySQL server and start running commands. type: mysql -uroot -p This will log you into MySQL as the root user. You’ll be prompted to enter the password you set in your docker-compose.yml file. \ Next, we need to create a special user that our replicas will use to connect to the master server and pull data. Inside the MySQL prompt, run the following commands: \ CREATE USER 'repl_user'@'%' IDENTIFIED BY 'replication_pass'; GRANT REPLICATION SLAVE ON . TO 'repl_user'@'%'; FLUSH PRIVILEGES; Here’s what’s happening: CREATE USER makes a new MySQL user called repl_user with the password replication_pass. GRANT REPLICATION SLAVE gives this user permission to act as a replication client. FLUSH PRIVILEGES tells MySQL to reload the user permissions so they take effect immediately. \ Time to Configure the Replica (Secondary) Servers a. First, let’s access the replica containers the same way we did with the master. Run this command in your terminal for each of the replica containers: \ docker exec -it <replica_container_name> bash mysql -uroot -p <replica_container_name> should be replace with the name of the replica container you are trying to setup b. Now it’s time to tell our replica where to get its data from. While inside the replica’s MySQL shell, run the following command to configure replication using the master’s details: CHANGE REPLICATION SOURCE TO SOURCE_HOST='mysql-master', SOURCE_USER='repl_user', SOURCE_PASSWORD='replication_pass', GET_SOURCE_PUBLIC_KEY=1; With the replication settings in place, let’s fire up the replica and get it syncing with the master. Still inside the MySQL shell on the replica, run: START REPLICA; This starts the replication process. To make sure everything is working, check the replica’s status with:
SHOW REPLICA STATUS\G; Look for Replica_IO_Running and Replica_SQL_Running — if both say Yes, congratulations! 🎉 Your replica is now successfully connected to the master and replicating data in real time.
Testing Our Replication Setup from the Node.js App Now that our replication is successfully set up, we can configure our Node.js server to observe the real-time effect of data being replicated from the master server to the replica server whenever we write to it. We start by installing the following dependencies:
npm i express mysql2 sequelize \ Now create a folder called src in the root directory and add the following files inside that folder connection.js, index.js and model.js. Our current directory should look like this We can now set up our connections to our master and replica server in the connection.js file as shown below
const Sequelize = require("sequelize"); const sequelize = new Sequelize({ dialect: "mysql", replication: { write: { host: "127.0.0.1", username: "root", password: "master", database: "replicaDb", }, read: [ { host: "127.0.0.1", username: "root", password: "slave", database: "replicaDb", port: 3307 }, { host: "127.0.0.1", username: "root", password: "slave", database: "replicaDb", port: 3308 }, { host: "127.0.0.1", username: "root", password: "slave", database: "replicaDb", port: 3309 }, ], }, }); async function connectdb() { try { await sequelize.authenticate(); } catch (error) { console.error("❌ unable to connect to the follower database", error); } } connectdb(); module.exports = { sequelize, }; \ We can now create a User table in the model.js file
const {DataTypes} = require("sequelize"); const { sequelize } = require("./connection"); const User = sequelize.define("User", { name: { type: DataTypes.STRING, allowNull: false, }, email: { type: DataTypes.STRING, unique: true, allowNull: false, }, }); module.exports = User \ and finally in our index.js file we can start our server and listen for connections on port 3000. from the code sample below, all inserts or updates will be routed by sequelize to the master server. while all read queries will be routed to the read replicas.
const express = require("express"); const { sequelize } = require("./connection"); const User = require("./model"); const app = express(); app.use(express.json()); async function main() { await sequelize.sync({ alter: true }); app.get("/", (req, res) => { res.status(200).json({ message: "first step to setting server up", }); }); app.post("/user", async (req, res) => { const { email, name } = req.body; let newUser = await User.build({ name, email, }); // This INSERT will go to the write (master) connection newUser = newUser.save({ returning: false }); res.status(201).json({ message: "User successfully created", }); }); app.get("/user", async (req, res) => { // This SELECT query will go to one of the read replicas const users = await User.findAll(); res.status(200).json(users); }); app.listen(3000, () => { console.log("server has connected"); }); } main(); When you make a POST request to the /users endpoint, take a moment to check both the master and replica servers to observe how data is replicated in real time. Right now, we are relying on Sequelize to automatically route requests, which works for development but isn’t robust enough for a production environment. In particular, if the master node goes down, Sequelize cannot automatically redirect requests to a newly elected leader. In the next part of this series, we’ll explore strategies to handle these challenges
