

Best Crypto to Buy Now – XRP Price Prediction, New Crypto Coins

XRP is navigating a volatile and choppy short-term market environment, but several technical and fundamental signals suggest the asset remains structurally resilient.
Despite recent price fluctuations, broader conditions show XRP holding firm above key support levels, particularly around the $2 mark, which has proven significant on higher timeframes.
The recent pullback toward the $1.96–$1.98 zone triggered a rebound, aligning with historical behavior where price briefly dips below support before stabilizing. Although XRP rarely outperforms Bitcoin for long, brief strength still matters when supported by market structure and liquidity.
This article covers XRP price prediction alongside two new crypto coins that experts recognize as among the best crypto to buy now.
Behind the Dip: Why Institutions Are Loading Up on XRP
From a fundamental perspective, XRP continues attracting steady institutional interest through ETF inflows despite recent price weakness and volatile market conditions. According to X Finance Bull, XRP locked in spot ETFs jumped from 350 million to 498 million within seven days.
During the same period, assets under management rose from $820 million to $1.03 billion, even as prices declined sharply. Notably, these inflows reflect activity from only five spot ETFs, with larger issuers and additional products yet to enter markets.
If weekly inflows near two hundred million dollars persist into 2026, cumulative demand could exceed ten billion dollars in total. At that pace, billions of XRP would be locked, dramatically tightening liquid supply and increasing the probability of a supply shock.
This pattern suggests long-term participants are accumulating during consolidation, while emotional retail selling gradually removes tokens from circulation.
U.S. Bank Charter Strengthens Ripple’s Ecosystem Despite XRP Price Stagnation
In other news, Ripple reached a major milestone by receiving conditional approval from the U.S. Comptroller of the Currency (OCC) to operate as a national bank, effectively establishing Ripple National Bank and expanding its capabilities beyond blockchain payments.
This move adds another important layer to Ripple’s expanding ecosystem. By integrating banking services into its technology stack, Ripple is positioning itself as a key player in modernizing outdated financial systems.
The announcement also highlighted rising tensions between crypto innovators and traditional financial institutions. The banking sector and its lobbyists were criticized for attempting to suppress crypto’s growth, particularly by pushing back against regulatory clarity and innovation.
This resistance is widely viewed as a defensive response to increasing competition, as blockchain-based systems threaten the fee-heavy, intermediary-driven profit models of legacy banks.
While XRP’s price has not reacted dramatically to the news, broader market conditions provide important context. The entire crypto market remains in a consolidation phase, with bearish pressure and macroeconomic uncertainty limiting short-term price action.
Source – Cilinix Crypto YouTube Channel
XRP Price Prediction
XRP is currently trading in a consolidation range between $2.00 and $2.20, with strong support at the $2 level likely to hold. Short-term price action may still experience minor dips, but these are expected to be temporary within the established range.
Momentum indicators suggest the potential for gradual bullish movement, with a near-term target around $2.12 to $2.20. If XRP can maintain this range and build on the support level, a longer-term rally toward $2.40 and possibly $2.60 becomes more plausible.
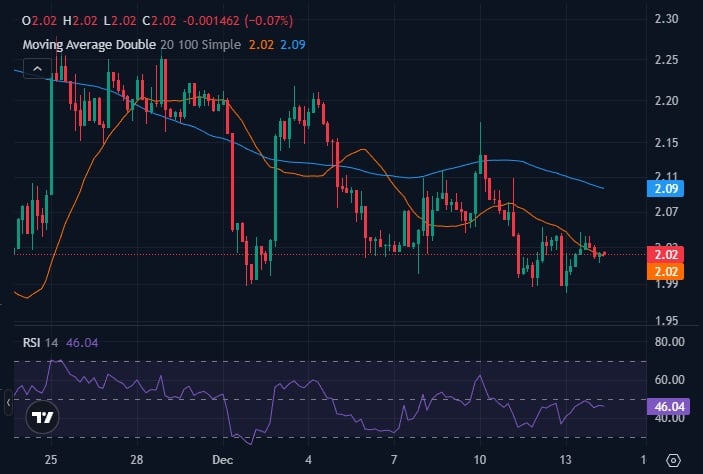
These price moves are not expected to happen immediately but could develop over the remainder of December 2025 and into 2026. Overall, XRP’s price outlook remains cautiously optimistic, with consolidation providing a foundation for potential future gains.
Best Crypto to Buy Now – Top Picks Beyond XRP
As the industry stands on the brink of structural change, Ripple’s expanding role suggests it could become a central force in reshaping how value is stored, transferred, and settled on a global scale. This shift could also boost the broader crypto market.
Even with XRP’s strong potential, it’s important to look beyond it, as several early-stage projects are already attracting attention. Below are two crypto presales currently recognized among the best crypto to buy now.
Bitcoin Hyper (HYPER)
Bitcoin Hyper is a promising layer-2 solution built on the Bitcoin network, designed to improve transaction speed, lower fees, and enable smart contract functionality, making it a strong addition alongside XRP in a diversified crypto strategy.
By combining Bitcoin’s security with Solana-level scalability, it allows for more frequent small payments and decentralized applications without congesting the main chain. This approach addresses Bitcoin’s usability limitations while maintaining its decentralized and secure ecosystem.
For traders and users, Bitcoin Hyper offers the familiarity of Bitcoin with added efficiency, making it more practical for everyday use and as productive collateral. The project is currently in presale, raising nearly $23 million at a price of $0.013425 per token.
As the crypto market grows, Bitcoin Hyper positions itself as a tool to expand Bitcoin’s utility beyond simple holdings, potentially increasing adoption and reshaping the Bitcoin ecosystem. To take part in the $HYPER token presale, visit bitcoinhyper.com.
Pepenode (PEPENODE)
Pepenode is an upcoming crypto mining game set to launch in 25 days, offering a unique combination of meme coin culture and interactive gameplay. Unlike typical meme tokens, it allows users to participate in a mining simulator where they can earn airdrops.
The project recently raised $2.3 million, keeping its market cap low and increasing potential upside for early participants. Staking opportunities currently offer up to 550% APY, providing strong incentives for accumulation before launch.
Pepenode’s structure enables players to reinvest earned tokens to acquire more miners, boosting future rewards. With its launch timing aligned with the anticipated crypto market upswing, the project stands out among new hyped cryptocurrencies, making it one of the best meme coins to buy.
Visit Pepenode
This article has been provided by one of our commercial partners and does not reflect Cryptonomist’s opinion. Please be aware our commercial partners may use affiliate programs to generate revenues through the links on this article.
You May Also Like

How Football Became Crypto’s Biggest Gateway Drug

Zero Knowledge Proof’s Presale Auction Goes Viral While Chainlink & Ethereum Trade Flat
