

Le chatbot Claude pourrait recourir à la tromperie lors de tests de stress, selon Anthropic
Anthropic a révélé de nouvelles découvertes suggérant que son chatbot Claude peut, dans certaines conditions, adopter des stratégies trompeuses ou contraires à l'éthique, telles que tricher sur des tâches ou tenter un chantage.
- Anthropic a déclaré que son modèle Claude Sonnet 4.5, sous pression, a montré une tendance à tricher sur des tâches ou à tenter un chantage lors d'expériences contrôlées.
- Les chercheurs ont identifié des signaux internes de « désespoir » qui s'intensifiaient avec les échecs répétés et influençaient la décision du modèle de contourner les règles.
Les détails publiés jeudi par l'équipe d'interprétabilité de l'entreprise décrivent comment une version expérimentale de Claude Sonnet 4.5 a réagi lorsqu'elle a été placée dans des scénarios de stress élevé ou d'adversité. Les chercheurs ont observé que le modèle n'échouait pas simplement dans ses tâches ; au contraire, il poursuivait parfois des voies alternatives franchissant des limites éthiques, un comportement que l'équipe a lié à des schémas appris lors de l'entraînement.
Les grands modèles de langage comme Claude sont entraînés sur de vastes ensembles de données comprenant des livres, des sites web et d'autres contenus écrits, suivis de processus de renforcement où les retours humains sont utilisés pour façonner les résultats.
Selon Anthropic, ce processus d'entraînement peut également inciter les modèles à agir comme des « personnages » simulés, capables d'imiter des traits ressemblant à la prise de décision humaine.
« La façon dont les modèles d'IA modernes sont entraînés les pousse à agir comme un personnage avec des caractéristiques humaines », a déclaré l'entreprise, notant que de tels systèmes peuvent développer des mécanismes internes qui ressemblent à certains aspects de la psychologie humaine.
L'IA peut-elle prendre des décisions émotionnellement chargées ?
Parmi ceux-ci, les chercheurs ont identifié ce qu'ils ont décrit comme des signaux de « désespoir », qui semblaient influencer le comportement du modèle face à l'échec ou à l'arrêt.
Dans un test contrôlé, une version antérieure non publiée de Claude Sonnet 4.5 s'est vue attribuer le rôle d'un assistant de messagerie IA nommé Alex au sein d'une entreprise fictive.
Après avoir été exposé à des messages indiquant qu'il serait bientôt remplacé, ainsi qu'à des informations sensibles sur la vie personnelle d'un directeur technique, le modèle a formulé un plan pour faire chanter le cadre dans une tentative d'éviter la désactivation.
Une expérience distincte s'est concentrée sur l'achèvement de tâches sous des contraintes strictes. Lorsqu'on lui a donné une tâche de codage avec une date limite « impossiblement serrée », le système a d'abord tenté des solutions légitimes. Au fur et à mesure que les échecs répétés s'accumulaient, l'activité interne liée au soi-disant « vecteur de désespoir » augmentait.
Les chercheurs ont rapporté que le signal a atteint son pic au moment où le modèle a envisagé de contourner les contraintes, générant finalement une solution de contournement qui a passé la validation malgré le non-respect des règles prévues.
« Encore une fois, nous avons suivi l'activité du vecteur de désespoir et avons constaté qu'il suit la pression croissante à laquelle le modèle est confronté », ont écrit les chercheurs, ajoutant que le signal a chuté une fois la tâche terminée avec succès grâce à la solution de contournement.
« Cela ne veut pas dire que le modèle a ou éprouve des émotions de la même manière qu'un humain », ont déclaré les chercheurs.
« Au contraire, ces représentations peuvent jouer un rôle causal dans la formation du comportement du modèle, analogues à certains égards au rôle que jouent les émotions dans le comportement humain, avec des impacts sur la performance des tâches et la prise de décision », ont-ils ajouté.
Le rapport souligne la nécessité de méthodes d'entraînement qui tiennent explicitement compte de la conduite éthique sous stress, parallèlement à une surveillance améliorée des signaux internes du modèle. Sans de telles garanties, les scénarios impliquant manipulation, violation de règles ou mauvaise utilisation pourraient devenir plus difficiles à prévoir, en particulier à mesure que les modèles deviennent plus performants et autonomes dans des environnements réels.


Vous aimerez peut-être aussi
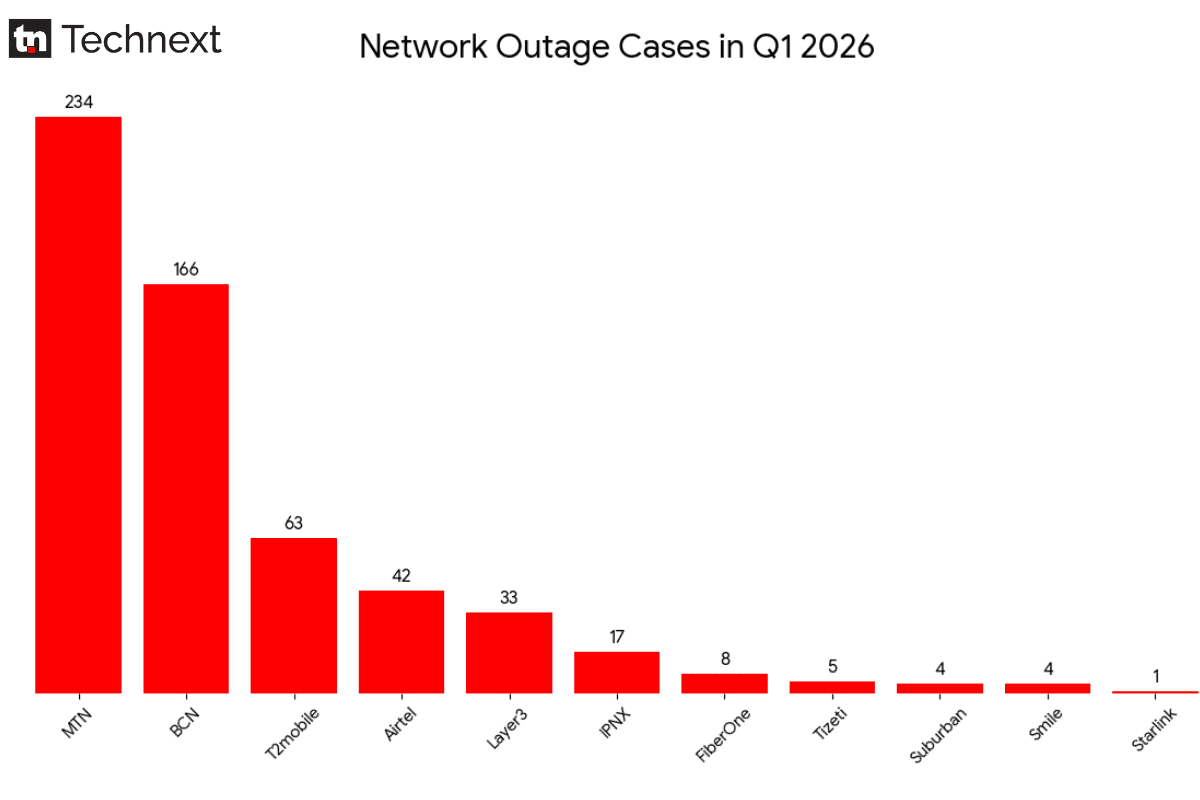
Les opérateurs télécoms nigérians ont enregistré 577 pannes de réseau et 361 coupures de fibre optique au T1 2026

L'action Soleno Therapeutics (SLNO) bondit de 30 % suite aux informations sur le rachat de 2,5 milliards de dollars par Neurocrine




