

Robust Mask-Guided Matting: Managing Noisy Inputs and Object Versatility
Table of Links
Abstract and 1. Introduction
-
Related Works
-
MaGGIe
3.1. Efficient Masked Guided Instance Matting
3.2. Feature-Matte Temporal Consistency
-
Instance Matting Datasets
4.1. Image Instance Matting and 4.2. Video Instance Matting
-
Experiments
5.1. Pre-training on image data
5.2. Training on video data
-
Discussion and References
\ Supplementary Material
-
Architecture details
-
Image matting
8.1. Dataset generation and preparation
8.2. Training details
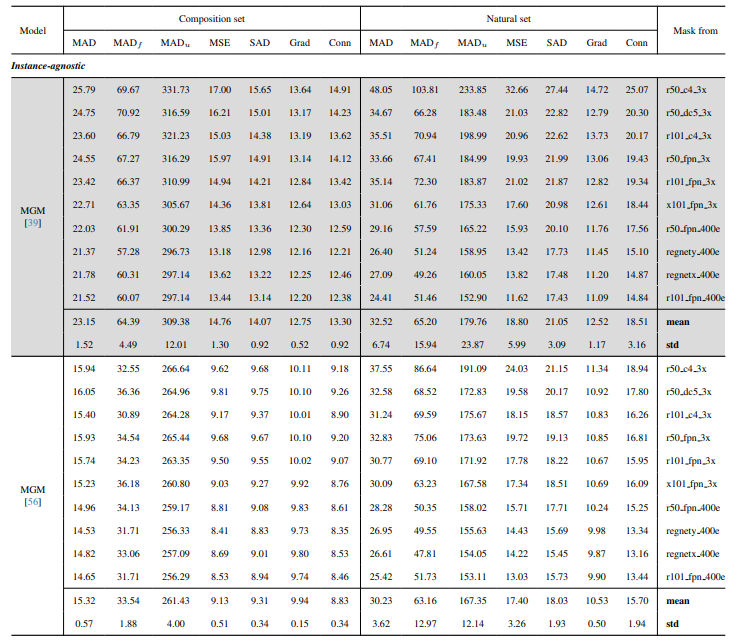
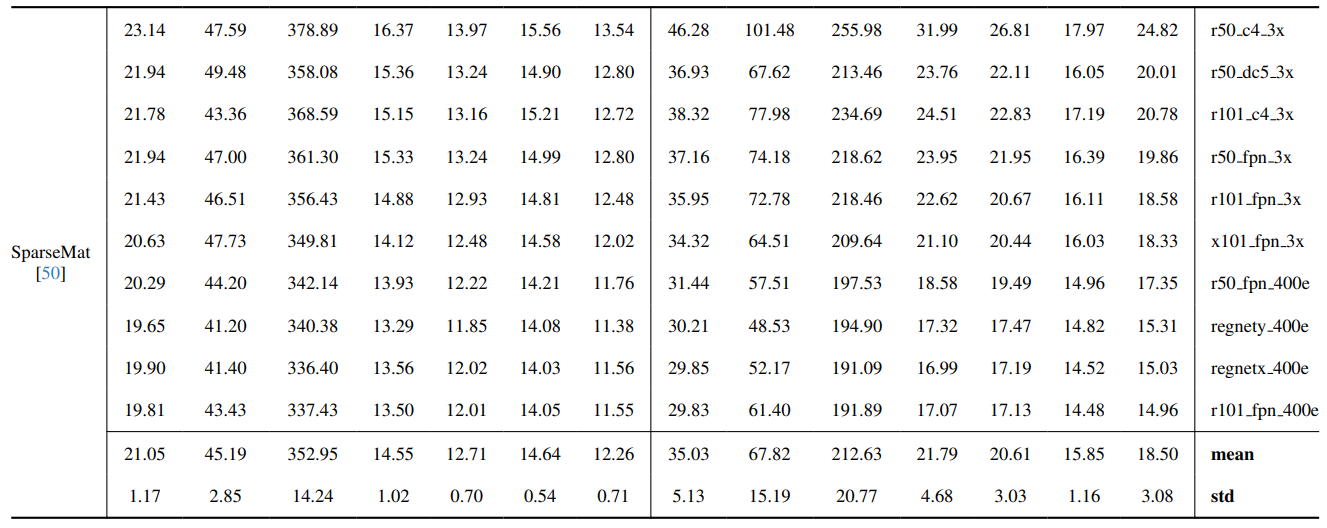
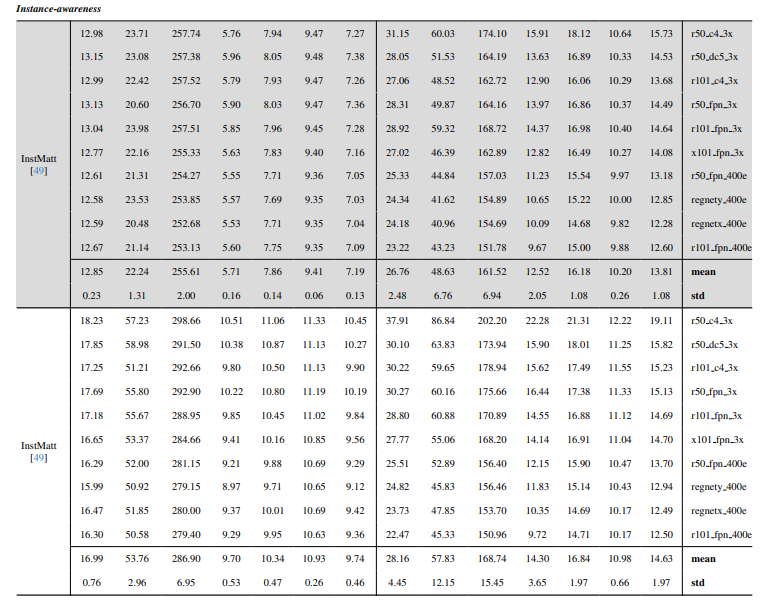
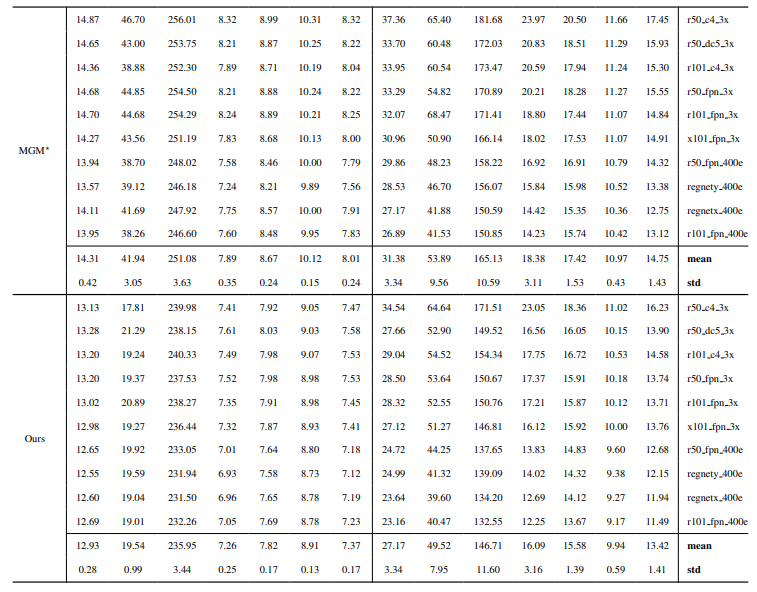
8.3. Quantitative details
8.4. More qualitative results on natural images
-
Video matting
9.1. Dataset generation
9.2. Training details
9.3. Quantitative details
9.4. More qualitative results
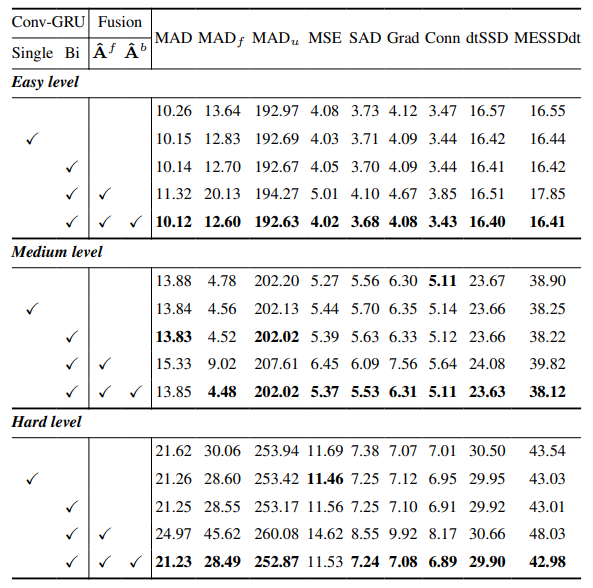
8.4. More qualitative results on natural images
Fig. 13 showcases our model’s performance in challenging scenarios, particularly in accurately rendering hair regions. Our framework consistently outperforms MGM⋆ in detail preservation, especially in complex instance interactions. In comparison with InstMatt, our model exhibits superior instance separation and detail accuracy in ambiguous regions.
\ Fig. 14 and Fig. 15 illustrate the performance of our model and previous works in extreme cases involving multiple instances. While MGM⋆ struggles with noise and accuracy in dense instance scenarios, our model maintains high precision. InstMatt, without additional training data, shows limitations in these complex settings.
\ The robustness of our mask-guided approach is further demonstrated in Fig. 16. Here, we highlight the challenges faced by MGM variants and SparseMat in predicting missing parts in mask inputs, which our model addresses. However, it is important to note that our model is not designed as a human instance segmentation network. As shown in Fig. 17, our framework adheres to the input guidance, ensuring precise alpha matte prediction even with multiple instances in the same mask.
\ Lastly, Fig. 12 and Fig. 11 emphasize our model’s generalization capabilities. The model accurately extracts both human subjects and other objects from backgrounds, showcasing its versatility across various scenarios and object types.
\ All examples are Internet images without ground-truth and the mask from r101fpn400e are used as the guidance.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Authors:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\
You May Also Like

Waarom Kyrgyzstan via Binance inzet op een stablecoin

Saudi blockchain real estate offers tokenized investment under Vision 2030
